


OOP 学习笔记(8)——STL 进阶
STL 进阶
string 字符串类
变长字符串
字符串是 char 的数组,但如果无法提前确认字符串长度,就不好处理。
可以使用vector<char>?实际上使用很不方便,比如输入输出。
因此 STL 提供了更方便的 string 类型。
可以使用简单的加法来拼接:
string str = "hello" + world;
也能够使用 cin、cout 来输入输出。
string 类常用构造及转换函数
string s0("Hello World!"); // 从 c 风格字符串构造
string s1; // 默认空字符串
string s2(s0, 6, 5); // 截取: World
string s3("Another character sequence", 12);
// 截取: another char
string s4(10, 'x'); // 赋值字符: xxxxxxxxxx
string s5(s0.begin(), s0.begin() + 5);
// 复制截取:Hello
string str("String");
str.c_str(); // 返回一个 c 风格常量字符串,不能修改
string 类基本使用方法
使用上与 vector 类似。
访问元素:
cout << str[1];
str[1] = 'a';
查询长度:
str.size();
清空:
str.clear();
查询是否为空:
str.empty();
迭代访问:
for (char c : str);
向尾部增加:
str.push_back('a');
str.append(s2); // 增加一个字符串
当然相比于 vector,还可以使用 str.length() 获取字符串长度,与 size() 返回值相同。(这里的长度都是真实的字符串长度,比如 "abc" 长度为 $3$)
string 类三种输入方式
cin >> firstname; // 读取可见字符直到遇到空白符(空格、换行符等)
getline(cin, fullname); // 读一行
getline(cin, fullnames, "#"); // 读到指定分隔符为止(可以读入换行符)
对于同一种输入:
Mike William
Andy William
#
三种方法的读入分别为:
Mike
Mike William
Mike William
Andy William
注意最后一种的结尾是一个换行符。
("Mike William\nAndy William\n")
数值类型的转换
to_string(1); // "1"
to_string(3.14); // "3.14"
to_string(3.1415926); // "3.141593" 注意精度损失
to_string(1 + 2 + 3); // "6" 先计算再传参
int a = stoi("2001"); // a = 2001
int b = stoi("50 cats", &sz); // b = 50 sz = 2 读入长度
int c = stoi("40c3", nullptr, 16); // c = 0x40c3 十六进制
int d = stoi("0x7f", nullptr, 0); // d = 0x7f 自动检查进制
double e = stod("34.5"); // e = 34.5
除此之外当然还有 stol()、stoll()、stof、stold、stoul、stoull 等函数,含义我觉得大家也猜得出来。
这里注意这些函数大多需要 C++11 乃至更新标准。
iostream 输入输出流
回忆:重载输出流运算符
cout << str << endl;
cin >> str;
ostream& operator<<(ostream& out, const Test& src)
{
out << src.id << endl;
return out;
}
但 istream、ostream 是什么?
STL 输入输出流
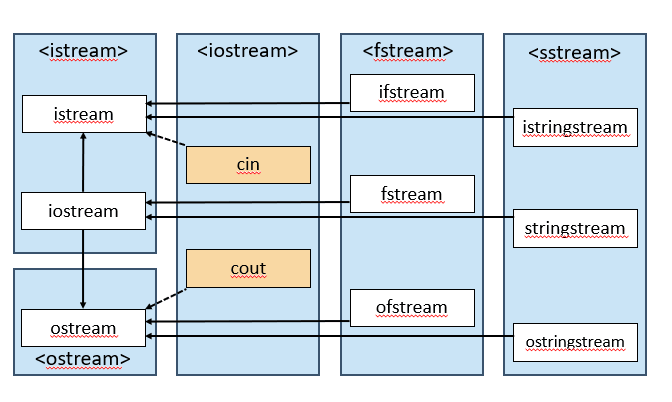
蓝色框是头文件,白色框为类,黄色框为对象,箭头为继承关系,虚线为实例化。
ostream 和 cout
ostream 即为 ouput stream,是 STL 库中所有输出流的基类。
它重载了针对基础类型的输出流运算符(<<),当然也有包括 string 在内的部分 STL 其他类也重载了输出流。
这种方法统一了输出接口,改善了 C 中输出方式混乱的状况。
(printf() 需要给出输出类型)
cout 是 STL 中内建的 ostream 类对象,它会将数据送到标准输出流 stdout(一般也就是屏幕上的显示)。
自己实现简单的 ostream
class ostream
{
public:
ostream& operator<<(char c)
{
printf("%c", c);
return *this;
}
ostream& operator<<(const char* str)
{
printf("%s", str);
return *this;
}
} cout;
int main()
{
cout << "hello" << ' ' << "world";
return 0;
}
实现原理:<< 运算符为左结合。
先执行 cout << "hello" 调用第二个函数返回 c1 (cout 的引用)。
再执行 c1 << ' ' 调用第一个函数返回 c2(cout 的引用)。
最后执行 c2 << "world" 调用第二个函数。
格式化输出
需要引用:
#include <iomanip>
然后就可以使用:
cout << fixed << 2018.0 << " " << 0.0001 << endl;
//浮点数,小数有效6位 -> 2018.000000 0.000100
cout << scientific << 2018.0 << " " << 0.0001 << endl;
//科学计数法 -> 2.018000e+03 1.000000e-04
cout << defaultfloat;
//还原默认输出格式
cout << setprecision(2) << 3.1415926 << endl;
//输出精度设置为2,包括整数+小数 -> 3.1
cout << oct << 12 << " " << hex << 12 << endl;
//八进制输出 -> 14 十六进制输出 -> c
cout << dec;
//还原十进制
cout << setw(3) << setfill('*') << 5 << endl;
//设置对齐长度为3,对齐字符为* -> **5
上述这些突然出现的“东西”都是流操纵算子。
fixed、scientific、defaultfloat、oct、hex、dec 等实现方法和 endl 一样,这是标准中定义的。
但有一些流操纵算子在规范里没有规定实现方式,不同编译器实现可能不同,比如 setprecision()、setw()、setfill() 等。
所以很难讲一共有多少种实现方式,但按道理来讲,在同一编译器内,应该就是分为不带参数和带参数两种。
流操纵算子:setprecision()
以 setprecision() 为例:
cout << setprecision(2) << 1.05 << endl;
// 保留 2 位精度,输出 1.1
一种可能的实现:
class setprecision
{
int precision;
public:
setprecision(int p) : precision(p) {}
friend class ostream;
};
class ostream
{
private:
int precision; // 记录流的状态
public:
ostream& operator<<(const setprecision &m)
{
precision = m.precision;
return *this;
}
} cout;
借助辅助类设置成员变量,这种类称为流操纵算子(stream manipulator)。
流操纵算子:endl
C++ 标准中 endl 的声明:
ostream& endl(ostream &os);
endl 是一个函数,等同于输出 '\n',再清空缓冲区 os.flush()。
ostream& endl(ostream &os)
{
os.put('\n');
os.flush();
return os;
}
可以调用 endl(cout)。
缓冲区:
- 目的是减少外部读写次数。
- 写文件时,只有清空缓存区或关闭文件才能保证内容正确写入。
但 endl 同时又是流操纵算子,这如何实现?
一种实现方式:
ostream& operator<<(ostream& (*op)(ostream&))
{
return (*op)(*this);
}
cout 不能复制
注意重载流运算符的方式,全部都采用了引用。
这是因为需要避免复制。
实际上:
ostream(const ostream&) = delete;
ostream(ostream&& x);
也就是禁止复制,只允许移动。
仅能使用一个对象可以:
- 减少复制开销;
- 一个对象对应一个标准输出,符合 OOP 思想;
- 多个对象之间无法同步输出状态。
当然这也会带来问题:全局对象往往引入初始化顺序问题。
其中涉及的单件模式(Singleton Pattern)之后应该会介绍。
文件输入输出流
以文件输入流作为例子,ifstream 是 istream 的子类,功能是从文件中读入数据。
一些基本打开操作:
ifstream ifs("input.txt");
ifstream ifs("binary.bin", ifstream::binary);
//以二进制形式打开文件
ifstream ifs;
ifs.open("file");
//do something
ifs.close();
读入示例:
ifstream ifs("input.txt");
while(ifs) // 判断文件是否到末尾 利用了重载的 bool 运算符
{
ifs >> ws; //除去前导空格 ws 也是流操纵算子
int c = ifs.peek(); //检查下一个字符,但不读取
if (c == EOF) break;
if (isdigit(c)) // <cctype> 库函数
{
int n;
ifs >> n;
cout << "Read a number: " << n << endl;
}
else
{
string str;
ifs >> str;
cout << "Read a word: " << str << endl;
}
}
其他操作:
getline(ifs, str),ifstream是istream的派生类,因此getline()仍然有效。get()用于读取一个字符。ignore(int n = 1, int delim = EOF)丢弃 $n$ 个字符,或者直至碰到delim分隔符。peek()检查下一个字符。putback(char c)返还一个字符。unget()返还一个字符。
istream 与 scanf()
为何 C++ 使用流取代了 scanf()?
scanf()不友好,不同类型要使用不同的标识符。- 安全性不好。
- 可拓展性差(自定义类)。
- 性能:
scanf()在运行期间需要对格式字符串进行解析,istream在编译期间已经解析完毕。
注:实际读入文件 cin 比 scanf 慢,因为默认 cin 与 stdin 总是保持同步,如果使用:
std::ios::sync_with_stdio(false);
取消同步后,scanf() 速度往往不如 cin。
stringstream 字符串输入输出流
字符串输入输出流
以输入输出流为作为例子。
stringstream 是 iostream 的子类。
iostream 继承于 istream 和 ostream。
stringstream 实现了输入输出流双方的接口。
可以发现这是一个多重继承关系。
stringstream
顾名思义:
- 它在对象内部维护了一个
buffer。 - 使用流输出函数可以将数据写入
buffer。 - 使用流输入函数可以从
buffer中读出数据。
一般用于程序内部的字符串操作。
构造方式:
stringstream ss; // 空字符串流
stringstream ss(str); // 以字符串初始化流
使用示例:
stringstream ss;
ss << "10";
ss << "0 200";
int a, b;
ss >> a >> b; // a = 100 b = 200
可以连接字符串,也可以将字符串转换为其他类型数据。
配合流操作算子,可以达到格式化输出效果。
获取 stringstream 的 buffer
ss.str() 返回一个 string 对象,内容就是 stringstream 的 buffer。
但注意 buffer 内容并不是未读取的内容,也就是即便经过了 >> 的部分也会被一起返回(仍然存在 buffer 中)。
实现一个类型转换函数
对于一般的类型:
int main()
{
string x = convert<string>(123);
int y = convert<int>("456");
cout << x << endl;
cout << y << endl;
return 0
}
一种简单的实现方法:
template <class outtype, class intype>
outtype convert(intype val)
{
static stringstream ss;
// 使用静态变量避免重复初始化
ss.str(""); // 清空缓冲区
ss.clear(); // 清空状态位(不是清空内容)
ss << val;
outtype res;
ss >> res;
return res;
}
状态位和缓冲区的差别,可以自己查看资料。
clear() 会清除错误标志位、流末位标志,如果不调用可能导致非法输入。
函数对象
排序
给定长度为 $n$ 的数组,如何最快地排序?
std::sort() 引用自 <algorithm> 一般来说是最好的选择。
template <class Iterator>
void sort(Iterator first, Iterator last);
具体使用:
int arr[5] = {3, 6, 2, 7, 1};
sort(arr, arr + 5);
for (int x : arr)
cout << x << " ";
// 1 2 3 6 7
但如果我们想降序呢?
注意到实际上 sort() 还重载了另一套参数:
template <class Iterator, class Compare>
void sort(Iterator first, Iterator last, Compare comp);
一种使用方法:
bool comp(int a, int b)
{
return a > b;
// comp 函数传入两个值,若 a 在 b 前,则返回 true,否则返回 false
}
sort(arr, arr + 5, comp);
// 7 6 3 2 1
函数对象
STL 提供了预定义的比较函数——<functional> 头文件。
从小到大:
sort(arr, arr + 5, less<int>());
从大到小:
sort(arr, arr + 5, greater<int>());
比较函数为何带括号?因为这是函数对象(仿函数)。
auto func = greater<int>();
cout << func(2, 1) << endl; // True
cout << func(1, 1) << endl; // False
cout << func(1, 2) << endl; // False
实现
template <class T>
class greater
{
public:
bool operator()(const T &a, const T &b) const
{
return a > b;
}
};
注意 sort() 函数要求:comp 不能修改数据。
一般情况下,comp 也不应该修改自身。
所以一般加上 const 标识符限定。
两种方法对比
bool comp(int a, int b)
{
return a > b;
}
sort(arr, arr+5, comp);
此时 sort() 的第三个参数是函数指针。
template<class T>
class greater
{
public:
bool operator()(const T &a, const T &b) const
{
return a > b;
}
};
sort(arr, arr+5, greater<int>())
此时第三个参数是函数对象。
一种 $O(n^2)$ 的sort() 实现
template<class Iterator, class Compare>
void sort(Iterator first, Iterator last, Compare comp)
{
for (auto i = first; i != last; i++)
for (auto j = i; j != last; j++)
if (!comp(*i, *j)) swap(*i, *j);
}
值得注意的是,std::sort() 的复杂度实际上是严格的 $O(n \log n)$,其中涉及到快速排序和堆排序算法在此教程暂不涉及。
自定义类型的排序
可以使用重载 < 运算符的方法。
但如果有多种排序方式的需求,则可以定义比较函数(或函数对象)。
STL 与函数对象
STL 中有大量函数用到了函数对象,在 <algorithm> 头文件中有:
for_each():对序列进行制定操作。find_if():找到满足条件的对象。count_if():对满足条件的对象计数。binary_search():二分查找满足条件的对象。
并且也有很多预置的函数对象,在 <functional> 头文件中有:
less:比较a < b。equal_to:比较a == b。greater:比较a > b。plus:返回a + b。
智能指针与引用计数
指针的销毁
A,B 对象共享一个 C 对象,C 对象不想交由外部销毁,那如何确定谁来销毁 C?
这是就可以引入智能指针。
智能指针
shared_ptr 来自 <memory> 库。(从 C++11 开始有)
构造方法:
shared_ptr<int> p1(new int(1));
shared_ptr<MyClass> p2 = make_shared<MyClass>(2); // 调用对应的构造函数
shared_ptr<MyClass> p3 = p2;
shared_ptr<int> p4; // 空指针
访问对象:
int x = *p1; // 从指针访问对象
int y = p2->val; // 访问成员变量
销毁对象:
p2,p3 指向同一对象,当两者均出作用域才会被销毁。
引用计数
为什么智能指针能够知道何时销毁对象?
因为其中有引用计数,只有当引用计数归为 $0$ 时,才会销毁对象。
shared_ptr<int> p1(new int(4));
cout << p1.use_count() << ' ';
{
shared_ptr<int> p2 = p1;
cout << p1.use_count() << ' ';
cout << p2.use_count() << ' ';
} //p2出作用域
cout << p1.use_count() << ' ';
输出为:
1 2 2 1
自己实现引用计数
#include <iostream>
using namespace std;
template <typename T>
class SmartPtr;
template <typename T>
class U_Ptr
{
private:
friend class SmartPtr<T>;
// SmartPtr 是 U_Ptr 的友元类
U_Ptr(T *ptr) : p(ptr), count(1) {}
~U_Ptr()
{
delete p;
}
int count;
T *p;
};
template <typename T>
class SmartPtr
{
U_Ptr<T> *rp;
public:
SmartPtr(T *ptr) : rp(new U_Ptr<T>(ptr)) {}
SmartPtr(const SmartPtr<T> &sp) : rp(sp.rp)
{
++rp->count;
}
SmartPtr& operator=(const SmartPtr<T> &rhs)
{
++rhs.rp->count;
if (--rp->count == 0) // 减少自身所指 rp 的引用计数 pA = pB
delete rp;
rp = rhs.rp;
return *this;
}
~SmartPtr()
{
if (--rp->count == 0)
delete rp;
}
T& operator*()
{
return *(rp->p);
}
T& operator->()
{
return rp->p;
}
};
int main()
{
int *pi = new int(2);
SmartPtr<int> ptr1(pi); // 构造函数
SmartPtr<int> ptr2(ptr1); // 拷贝构造
SmartPtr<int> ptr3(new int(3)); // ptr3(pi) 会怎样?
ptr3 = ptr2; // 注意赋值运算
cout << *ptr1 << endl;
*ptr1 = 20;
cout << *ptr2 << endl;
return 0;
}
注意此处并没有实现空指针以及直接调用构造函数的写法,只是实现了存储指针。
其他用法
p.get()获取裸指针;p.reset()清除指针并减少引用计数;static_pointer_cast<int>(p);dynamic_pointer_cast<Base>(p)。(基类指针)
注意:
- 不能使用同一个裸指针初始化多个智能指针,会导致产生多个辅助指针。
不能直接使用智能指针维护数组对象。
(所有的实现中都是使用
delete p;,但是数组却是delete [] p;)智能指针不总是智能。
#include <memory> #include <iostream> using namespace std; class Child; class Parent { shared_ptr<Child> child; public: Parent() { cout << "parent constructing" << endl; } ~Parent() { cout << "parent destructing" << endl; } void setChild(shared_ptr<Child> c) { child = c; } }; class Child { shared_ptr<Parent> parent; public: Child() { cout << "child constructing" << endl; } ~Child() { cout << "child destructing" << endl; } void setParent(shared_ptr<Parent> p) { parent = p; } }; void test() { shared_ptr<Parent> p(new Parent()); shared_ptr<Child> c(new Child()); p->setChild(c); c->setParent(p); // p 和 c 被销毁 } int main() { test(); return 0; }输出为:
parent constructing child constructing因为结束时两个对象的引用次数都是 $1$,内存泄漏!
解决方法为:
class Child { weak_ptr<Parent> parent; public: Child() { cout << "child constructing" << endl; } ~Child() { cout << "child destructing" << endl; } void setParent(shared_ptr<Parent> p) { parent = p; } };输出为:
parent constructing child constructing parent destructing child destructing弱引用
weak_ptr指向对象但不计数。也就是说,在函数结束前,
Parent的计数为 $1$,Child的计数为 $2$。而
Parent就可以正常销毁,并使得Child的计数也减少 $1$,此时Child也能正常销毁。
弱引用
弱引用指针的创建:
shared_ptr<int> sp(new int(3));
weak_ptr<int> wp1 = sp;
用法:
wp.use_count(); // 获取引用计数
wp.reset(); // 清除指针
wp.expired(); // 检查对象是否无效
sp = wp.lock(); // 从弱引用获得一个智能指针
实例:
std::weak_ptr<int> wp;
{
auto sp1 = std::make_shared<int>(20);
wp = sp1;
cout << wp.use_count() << endl; // 1
auto sp2 = wp.lock(); // 从弱引用中获得一个shared_ptr
cout << wp.use_count() << endl; // 2
sp1.reset(); // sp1 释放指针
cout << wp.use_count() << endl; // 1
} // sp2 销毁
cout << wp.use_count() << endl; // 0
cout << wp.expired() << endl; // 检查弱引用是否失效:True(已失效)
独享共有权
shared_ptr 涉及引用计数,性能较差。
如果要保证一个对象只被一个指针引用,可以使用 unique_ptr:
auto up1 = std::make_unique<int>(20);
// unique_ptr<int> up2 = up1;
// 错误,不能复制 unique 指针
unique_ptr<int> up2 = std::move(up1);
// 可以移动 unique 指针
int* p = up2.release();
// 放弃指针控制权,返回裸指针
delete p;
智能指针总结
- 优点:
- 只能指针可以帮助管理内存,避免内存泄漏。
- 区分
unique_ptr和shared_ptr能够明确语义。 - 在手动维护指针不可行,复制对象开销太大时,智能指针是唯一选择。
- 缺点:
- 性能会受到影响。
- 智能指针不总是智能,需要了解内部原理。
- 需要小心环状结构和数组指针。
lambda 表达与 STL 函数封装
lambda 表达式
可以一行创建函数吗?(别跟我说缩代码)
这时可以引入 lambda 表达式——简便地创建匿名函数的方法。
int a = 1;
auto func = [a](int x) { return a + x; };
cout << func(2) << endl; // 3
参数列表和函数体
对应真实函数的参数列表和函数体,较容易理解。
捕获列表
int a = 1;
auto func = [a](int x) { return a + x; };
a = 2;
cout << func(2) << endl; // 3 还是 4 ?
实际上这种捕获方式为按值捕获,在函数声明的一刻,确定捕获变量的值,所以会输出 $3$。
当然还有按引用捕获,也就是在函数声明的一刻,确定捕获变量的引用。
int a = 1;
auto func = [&a](int x) { return a + x; };
a = 2;
cout << func(2) << endl; // 输出4
一般来说有以下常见用法:
[]:不捕获变量。[a, &b]:按值捕获a,引用捕获b。[this]:按值捕获this指针。[=]:按值捕获所有外部变量。[&]:按引用捕获所有外部变量。[=, &a]:按引用捕获a,其与变量按值捕获。[&, =a]:按值捕获a,其余变量按引用捕获。
注意,当按引用捕获时,是可以修改外部变量的值的。
而如果按值捕获,一般而言传入的值不能被修改(非左值),如果想要修改,需要加上 mutable 标识符(当然修改的只是传入的副本,不会影响外界):
auto func = [a](int x) mutable { a = 3; return a + x; };
返回值
在没有指定的情况下,lambda 表达式会自动推断。
如果想要指定,可以使用:
auto func = [a](int x) mutable -> int { a = 3; return a + x; };
(-> auto 的用法与一般函数一样需要 C++14)
使用 lambda 表达式的优点
- 更加简洁;
- 只使用一次的函数无需命名,避免污染变量空间;
- 增加相关代码的内聚性。
实际上在前面提到过 sort() 函数的第三个参数中,也可以使用 lambda 表达式以简化代码。
同样也可以配合模板函数(成员函数)使用(编译期进行绑定)。
但如果想要动态绑定,比如:
class MyArray : public vector<int>;
bool lessThan3(int x)
{
return x < 3;
}
arr.setFunc([](int a) { return a < 3; });
cout << arr.find() << endl;
arr.setFunc(lessThan3);
cout << arr.find() << endl;
这就不能用模板在编译期进行绑定。
如何储存不同类型的函数指针和函数对象?
function 类
function 类提供了函数指针与函数对象的封装:
class MyArray : public vector<int>
{
private:
function<bool(int)> fn; // 表示参数为 int,返回值为 bool
// 能够接受函数指针、匿名函数、函数对象
public:
void setFunc(function<bool(int)> _fn)
{
fn = _fn;
}
int find()
{
for (auto i : (*this))
if (fn(i)) return i;
}
};
函数对象的组合
比如如何用 STL 库组合出 lessThan3() 函数?
bind(less<int>(), placeholders::_1, 3);
其中:
bind()是<functional>库函数。less<int>()是被绑定的函数。placeholders::_1:被绑定函数的第一个参数来自新函数的第一个参数。3:被绑定函数的第二个参数为 $3$。
其返回值为一个函数对象,功能与 lessThan3() 一致。
同样,甚至可以使用 less 组合出 greater。
字符串处理与正则表达式
正则表达式
正则表达式是搜索文本时定义的一种规则。
给定一个正则表达式和另一个字符串。
- 匹配整个字符串是否满足条件。
- 查找符合正则表达式的子串。
- 按规则替换字符串的部分。
比如一个正常邮箱地址的通用正则表达式为:
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
(看起来长的很不友善,反正我也不会)
基本模式
- 字符代表其本身:
once匹配句子中所有的once。 - 转义字符:
\n表示换行,\t表示制表符,后面会提到的各种通配符如果需要用到本身,也可以使用前面加一个\来表示,比如\.。 - 特殊匹配字符:
^代表开头,$代表结尾。^\t只能匹配到以制表符开头的内容。^bucket$只能匹配到只含bucket的内容。
字符簇
- 匹配的单个字符在某个范围中:
[aeiou]匹配任意一个元音字符。[a-z]匹配所有单个小写字母。[0-9]匹配所有单个数字。
- 范围取反:
[^a-z]匹配所有单个非小写字母。
- 连用:
[a-z][0-9]:- 匹配所有字母 $+$ 数字的组合,比如
a1,b9。 ^[^0-9][0-9]$:- 用于匹配 $2$ 个长度的内容,且第一个不为数字,第二个为数字。
- 特殊字符:
.匹配出换行符以外任意字符。\d等价[0-9]。\D等价[^0-9]。\s匹配所有空白字符。\S匹配所有非空白字符。\w匹配字母、数字、下划线。\W匹配非字母、数字、下划线。\b匹配单词边界,或者说它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w。\B匹配非单词边界。
重复模式
x{n,m}代表前面内容出现次数重复 $n \sim m$ 次($0 \le n \le m$):a{4}匹配aaaa。a{2,4}匹配aa或aaa或aaaa。a{2,}匹配长度大于等于 $2$ 的a。
- 扩展到字符簇:
[a-z]{5,12}代表长度为 $5 \sim 12$ 的英文小写字母组合。.{5}所有长度为 $5$ 的字符,除换行符外。
- 特殊字符:
?等价{0,1}。+等价{1,}。*等价{0,}。
或连接符
匹配模式可以使用 | 进行连接。
(Chapter|Section)[1-9][0-9]?可以匹配Chapter 1、Section 10等。0\d{2}-\d{8}|0\d{3}-\d{7}可以匹配010-12345678、0376-2233445等。
其中使用的 () 可以改变优先级。
m|food可以匹配m或者food。(m|f)ood可以匹配mood或者food。
一个例子:
((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
可以匹配所有可能的 IP 地址(IPv4)。
分组
以 () 标识的部分被称作分组:
- 正则表达式匹配后,每个分组的内容将被捕获。
- 用于提取关键信息,例如
version(\d+)即可捕获版本号。
分组会按顺序标号:
- $0$ 号永远是匹配的字符串本身。
(a)(pple)中 $0$ 号为apple,$1$ 号为a,$2$ 号为pple。
使用 (?:pattern) 可以不捕获该分组。
更多内容
- 预查:
- 正向预查
(?=pattern)(正向肯定预查)、(?!pattern)(正向否定预查)。 - 反向预查
(?<=pattern)(反向肯定预查)、(?<!pattern)(反向否定预查)。 - 预查不会移动匹配指针,也就是其只是一个预先或者后置的匹配。
- 具体可以参见这里。
- 正向预查
- 后向引用:
\b(\w+)\b\s+\1\b匹配重复两遍的单词,比如go go或kitty kitty。- 这里的
\1即代表需要与第一个分组中内容相同。
- 贪婪与懒惰
- 默认多次重复为贪婪匹配,即匹配次数最多。
- 在重复模式后加
?可以变为懒惰匹配,即匹配次数最少,比如.*?。
原生字符串
- 正则表达式往往会有很多
\,字符串表示时应该写为\\。 原生字符串可以取消转义,保留字面值。
语法:
R"(str)"表示str的字面值。比如:
"\\d+" = R"(\d+)" = \d+。原生字符串可以换行,比如:
auto str = R"(Hello World)";- 结果
str = "Hello\nWorld"。
正则表达式库 <regex>
正则表达式匹配的三种模式:
- 匹配:
- 询问字符串是否能匹配正则表达式,并捕获响应分组。
regex_match()。
- 替换:
- 替换字符串中匹配的子串,并替换成相应内容。
regex_replace()。
- 搜索:
- 搜索字符串中匹配的子串,并捕获相应分组。
regex_search()。
匹配实例:
string s("subject");
regex e(R"((sub)(.*))");
smatch sm;
regex_match(s,sm,e);
cout << sm.size() << " matches\n";
cout << "the matches were: ";
for (unsigned i=0; i<sm.size(); ++i)
{
cout << "[" << sm[i] << "] ";
}
输出为:
3 matches
the matches were: [subject] [sub] [ject]
更多用法请自行探索。


Comments: 4
匹配 Email 的那个正则看起来有问题,应该是
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}看起来又是 markdown 编辑器出锅了。
还是不对,大括号里{2,14}不能有空格
习惯性打的,,忘记了