


天眼——基于口罩识别的无人机
本项目是北京大学信息科学技术学院 2019 年春季学期 AI 引论课程智能机器人小班的小组课题,孩子才疏学浅故许多功能有待完善,ddl 压迫故部分效果不甚理想,欢迎各位大佬的建议与指正 QAQ。
项目背景
前段时间疫情严重,而仍时常有不佩戴口罩的现象发生。因此我们希望制作一款能自动巡逻检测口罩佩戴情况并进行提醒的机器人,来维护社会秩序减轻社区工作人员压力。经过调研我们发现已经有高新兴的轮式机器人出现在抗疫前线;而相较于市面上已经有的轮式机器人,我们认为轻量化的无人机能更快速高效的完成这项任务,也可以更好的进行室外的作业。经过广泛的调研及资料查阅后,我们决定设计一款基于口罩识别的无人机。并由组长起名为天眼……

不是这个!
运行环境与功能设计
- 系统:Windows 10
- 虚拟平台:Webots(R2020a)
- 机器学习框架:Pytorch
- 需要补充的 Python 库:OpenCV,PIL
基于 Webots 平台的 dji_mavic_pro_2 飞行器,我们增加了一些传感器节点,编写了新的控制器并实现信息交互的接口以实现一款能巡逻维护治安的无人机。简而言之,我们基本实现了稳定飞行、自主避障、口罩识别、语音提醒的功能,不过由于时间和精力所限没能完成最初设计的如自主路线规划以及无人机网络的功能,也有一些遗憾。


功能介绍
1.稳定飞行
不同于轮式机器人,无人机很容易翻车……一言不合原地螺旋升天飞出屏幕。
好在 Webots 自带 demo 的控制器中已经有了以下功能:
- Stabilize the robot using the embedded sensors.
Use PID technique to stabilize the drone roll/pitch/yaw.
Use a cubic function applied on the vertical difference to stabilize the robot vertically.
Stabilize the camera.
Control the robot using the computer keyboard.
具体实现应用了许多Webots自带的库函数不再赘述(俺也不会)。最终效果可以使得无人机在平面内平稳飞行以及调整目标高度,效果如下:

老哥,稳!
2.自动避障
王老师自主设计并手写了避障的代码,大致思路如下:在无人机上添加三个 distance sensor 节点,并调整它们的位置的方向使其能探测正前方和左、右前方障碍物的距离。修改传感器的查找表,使其能在较远距离感知障碍物,并在控制器里添加判断前方一定距离是否有障碍物的函数。通过调节参数编写在判断前方一定距离内有障碍物时右转避开并在避开障碍物后回复正常状态的函数。
进行大量测试后,根据效果调整传感器探测距离和飞行参数。最终能实现在一定高度起飞时通过提前检测并向右飞行来避开障碍物,并且在避开障碍物后能够重新恢复向前飞行的状态。经测试可以连续多次避障。在一定高度起飞时可以保持稳定高度向前飞行,并且不出现翻倒的情况。

图中演示了避障的全过程。
3.口罩识别
啊哈,这部分是我负责的,介绍的详细一点。
口罩识别功能直接调用了 Github 上的开源项目,由 AIZOO 提供的 FaceMaskDetection-master,具体实现不再赘述(其实是神经网络啥的俺也不太会,仅限于看懂)(项目链接点此)先来看看在本地摄像头运行的效果:

尽管该项目的设计者已经尽可能的减小模型,由于设备性能问题帧率依旧不是很高,在本地摄像头运行时有卡顿感。
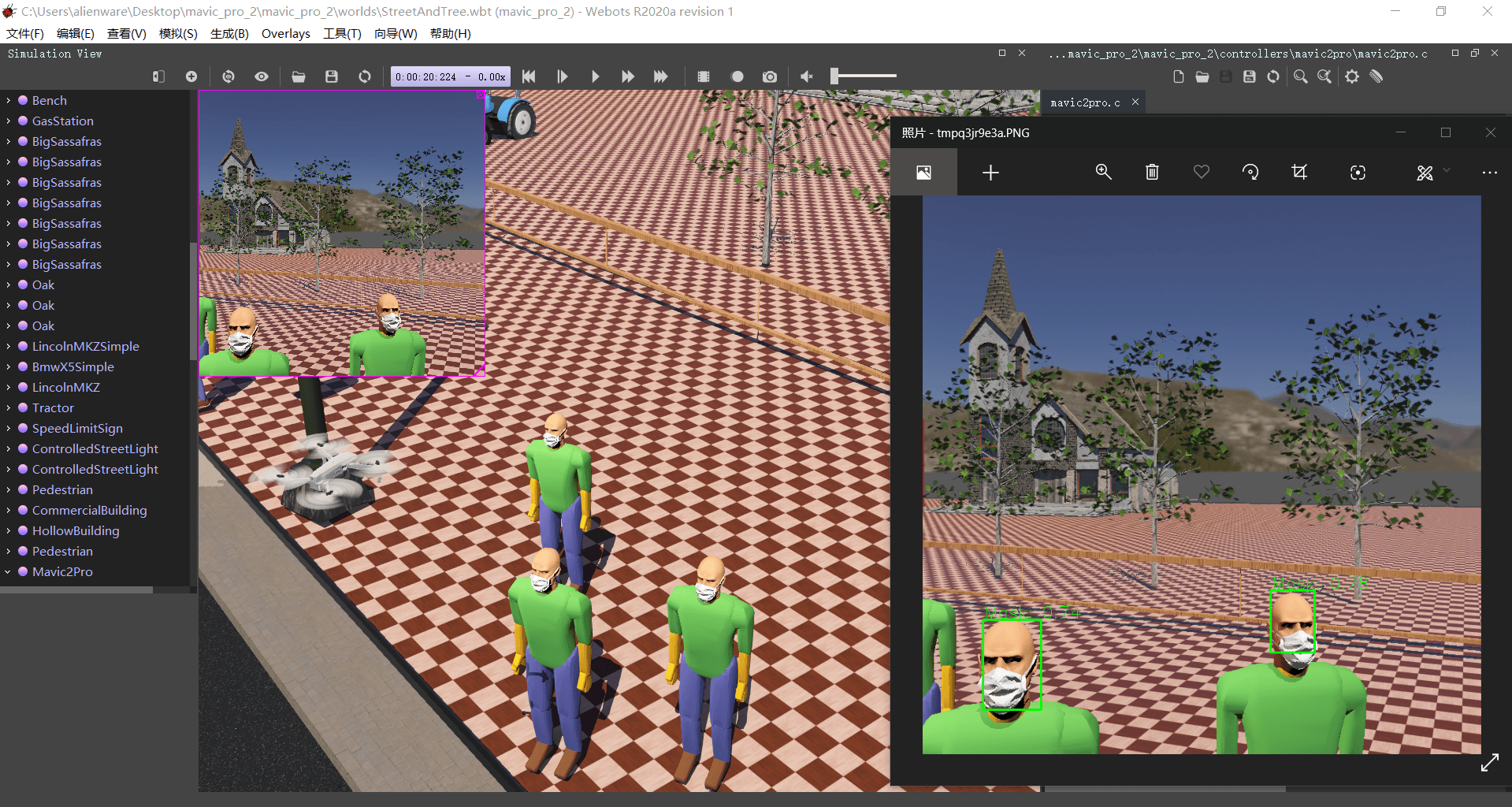
考虑到本项目要在虚拟平台上运行,我们测试了对建模的人体的识别效果,结果如下。可以看到该模型对于建模的面部以及口罩识别同样有着较好的运行结果。出于性能等需求我们希望尽量将人体的建模简单化,因此对更加简化的模型也测试了准确率,结果良好。这样的效果也表明口罩识别对图像的清晰度等要求较低,即使飞行器从较远距离拍摄到的小人脸也可以准确识别,对项目的可行性及后续处理都是一个好消息。

逐渐贝恩化……

在完成对识别部分计算机视觉工作的验证后,我们所要做的就是在飞行器所拍摄的画面上运行上面的程序,获取识别结果。
Webots 中的飞行器(我们采用的是 dji 的 mavic_2_pro)已经设置了 camera 装置用以拍摄画面,同时也达成了维持稳定的功能,已经可以得到较为稳定清晰的画面,因此不再考虑改进。不过 camera 初始的像素仅为 400×240,若有需要可以考虑增高图像品质,直接修改 camera 的 Height 与 Width 参数即可。
考虑到识别部分的代码为 python,而我们的机器人的主体部分代码采用C语言。而同时将 python 与 Webots 软件直接结合较为困难,因此我们采用了 C 语言的 system 函数,用它来传递 DOS 指令以运行口罩识别部分的代码。同时,Webots 自带函数 wb_camera_save_image 可以将某个 camera 控件的画面保存到本地。
#include <webots/camera.h>
int wb_camera_save_image(WbDeviceTag tag, const char *filename, int quality);
但完成基本的功能实现后,面临着性能的问题。我开始先测试了将 camera 所得画面录制为视频并在视频上运行口罩识别代码,但由于识别所花费的时间较长,视频也仅仅能识别一段时间中几帧的画面,效果与图片几乎没有区别。同时考虑到现实应用中拍摄到的人往往会在画面中停留一段时间,并且口罩识别的运行也需要一定的时间,于是我选择了合适的时间间隔,每隔一段时间进行一次图片保存以及口罩识别操作。根据设备性能的差异可以更改 runtimegap 以实现性能开销和画面识别密度的平衡。最终代码如下:
#define runtimegap 1000;
int runpic = 0;
while (wb_robot_step(timestep) != -1) {
//其余部分代码略,仅展示相关部分
runpic++;
if (runpic == runtimegap)
{
wb_camera_save_image(camera,"1.png",1);
system("python pytorch_infer.py --img-path 1.png");
runpic = 0;
}
}
测试运行,效果如下(注: 测试用 camera 大小为 800×800 (像素) ):

由于模拟的精度等问题,识别结果不算太过准确,对于下图左边这个肉眼可见明显戴着口罩的模型判定的戴口罩概率仅为 0.70。当然如果把航拍的默认高度降低到与人体身高相仿准确率能高上不少,如右边的测试结果,但出于安全(无人机骑脸)以及设备维护考虑最终还是选择选取较高的目标高度,而且毕竟现实中的人也不会长成这样 QAQ。

最后看看成品大致效果,无人机在飞行过程中检测到未佩戴口罩的人后显示拍摄到的画面。卡顿是因为 system 函数占用当前线程了,实体无人机就不会出现模拟中止的情况了无伤大雅(懒的写多线程)。
4.语音提示
每次识别获得结果后利用文件读写进行 c++ 与 Python 的信息交互并在识别出未佩戴口罩时进行提醒。音频结果难以演示,在建立 speaker 节点后主要代码实现如下:
wb_speaker_speak(speaker, "Sorry, you are not wearing a mask", 1);
这样就可以发出“Sorry, you are not wearing a mask”的提示音,当然你也可以把提示音改为“BB没……”或播放一首葫芦娃或令无人机上的指示灯闪烁。
设想与展望
关于自主路线规划,如果仅仅给出移动到充电站坐标的指令配合避障功能也可以简单的实现,但我们更希望它能通过自主探测获取环境信息,并自己设计前进路线来达成目标
无人机网络,既可以可以避免部分无人机出故障,也可以根据人流变化改变各区域分配数目,实现更多复杂的功能。可惜虚拟平台性能所限,多无人机运行会有些卡顿;最终ddl临近我们也来不及实现这个功能。但我认为这个构想是极好的QAQ
疫情似乎即将过去,将口罩识别的接口换为呼救识别、事故识别等等也可以继续实现维护社会治安的功能,口罩识别只是它的无限可能之一

想说的话
感谢退课了仍和我们一起完成这个项目的组长以及辛勤付出的队友 QAQ,也感谢在孩子遇到困难时给予帮助的帅比学长。
Webots 平台的有关资料真的很少,做这个项目也可谓是面向 csdn 和 github 以及王海 (wzf2000,永远滴神),同时虚拟平台建模精度以及性能要求都对项目带来了很大的挑战。虽然 AI 引论是门垃圾课(×),但这个项目确实令我受益匪浅。
不太会用 ros,许多功能也没能实现,有点遗憾。
有时想想我们现在所做的东西也仅仅是将前人工作东拼西揍而成的缝合怪,希望自己有能力后能做出真正有意义的项目吧。
第一次专门为 wzf2000.top 写文章,孩子比较菜请多包涵 (别骂了别骂了) 。
感谢阅读!



Comments: 1
github项目用的倒是挺溜嘛